
Building a Scalable macOS GitHub Actions Runner Platform
The Challenge: Scaling macOS CI/CD Infrastructure
As our iOS and macOS development teams grew, we encountered a critical bottleneck in our continuous integration and delivery pipeline. Our GitHub Actions workflows were experiencing queue times averaging 90 minutes during peak hours, significantly impacting developer productivity and release velocity.
This challenge emerged from the unique constraints of macOS-based CI/CD at scale. Unlike Linux-based runners that can be efficiently managed in Kubernetes environments, macOS runners require specialized infrastructure due to Apple’s licensing requirements, virtualization framework limitations, and the use of dedicated AWS EC2 Mac instances.
We identified three interconnected challenges that needed to be addressed:
- Extended Queue Times: Developers experienced wait times of 60-90 minutes for runner availability during peak hours, resulting in decreased productivity and prolonged feedback cycles.
- Inefficient Resource Utilization: Maintaining macOS EC2 instances at peak capacity 24/7 resulted in substantial costs for idle infrastructure during off-peak hours, nights, and weekends.
- Complex Operational Overhead: Capacity adjustments required manual intervention, AMI updates necessitated system downtime, and there was no mechanism for graceful node maintenance without disrupting active workflow executions.
While GitHub’s Actions Runner Controller provides an excellent solution for Linux runners in Kubernetes environments, the unique characteristics of macOS infrastructure—including Apple’s licensing requirements, Virtualization.framework constraints, and AWS’s specialized EC2 Mac instances—required a purpose-built approach.
Our objective was to develop a system capable of dynamic scaling, intelligent resource management, and zero-downtime operations specifically optimized for macOS runner workloads.
Our Solution: A Kubernetes-Inspired Control Plane for macOS
We developed a custom control plane specifically architected for managing macOS GitHub Actions runners on AWS infrastructure. The design incorporates proven patterns from Kubernetes orchestration while adapting them to address the specific constraints and requirements of macOS virtualization environments.
Core Architecture
The system consists of four main components working together:
- Controller: The brain of the system, managing the lifecycle of both nodes (EC2 macOS instances) and runners (GitHub Actions runners). It maintains the desired state and reconciles it with actual state.
- Scheduler: Matches pending runner requests with available node capacity, considering CPU requirements, memory constraints, and current node utilization.
- Tarter Daemon: Runs on each macOS node, acting as a node agent that provisions and manages Tart VMs (macOS virtual machines) and reports health back to the controller.
- Scaler: Adjusts the EC2 instance pool based on demand and schedule, ensuring we have capacity when needed and reducing costs during off-hours.
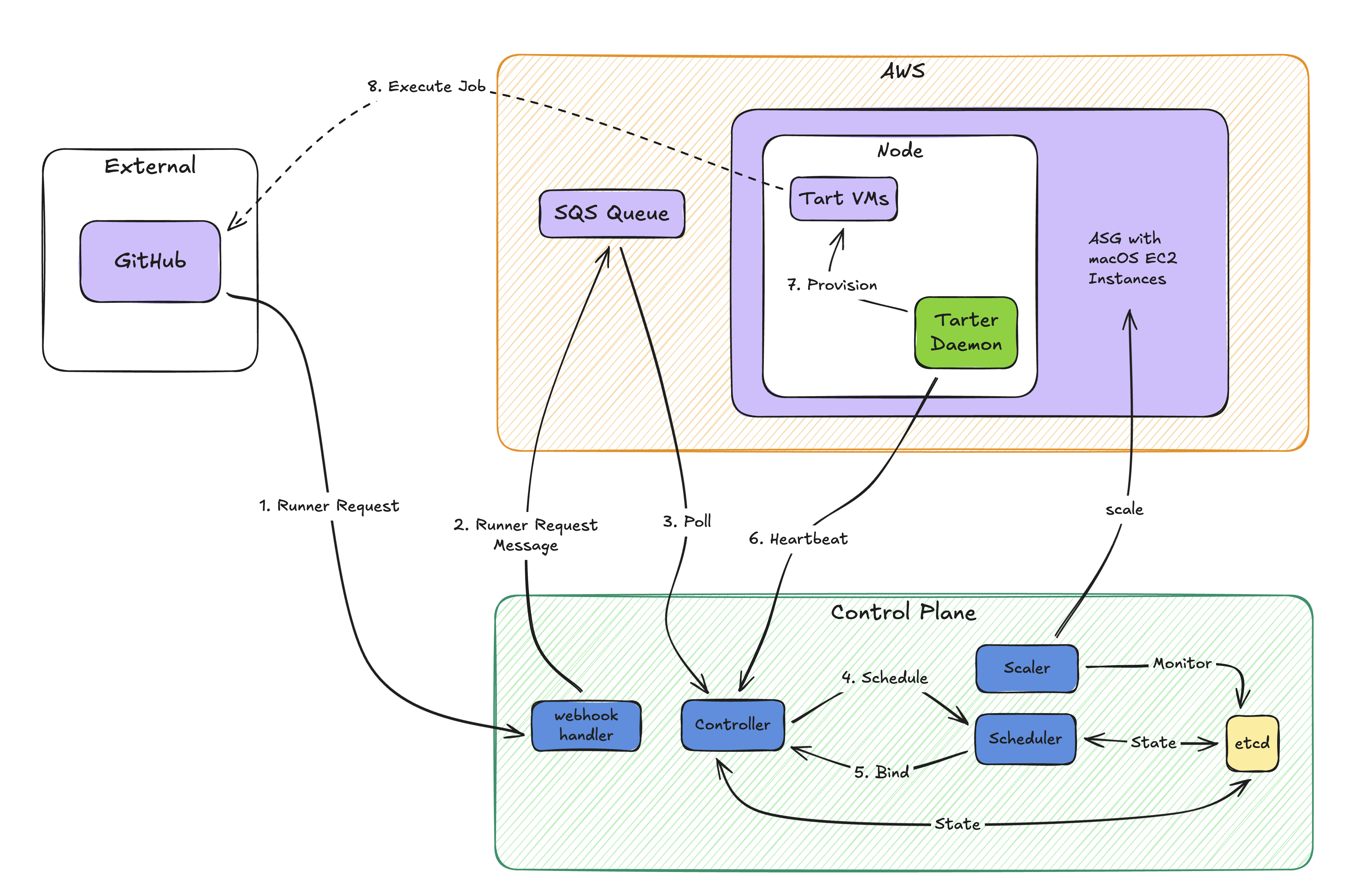 Figure 1: High-level system architecture showing the interaction between control plane components, AWS infrastructure, and macOS nodes
Figure 1: High-level system architecture showing the interaction between control plane components, AWS infrastructure, and macOS nodes
How It Works: The Runner Lifecycle
The following sequence illustrates the complete lifecycle of a runner from request to completion:
1. Runner Request
When GitHub needs a runner, it sends a webhook. Our system receives this via AWS SQS, creating a Runner entity with resource requirements (e.g., 4-core or 8-core macOS, Xcode version).
2. Scheduling
The Scheduler service scans all available nodes every few seconds, looking for a node with:
- Sufficient CPU capacity
- Available memory
- Healthy status
If no node has capacity, the runner stays in “Pending” state. If multiple nodes match, the scheduler picks the best fit to optimize bin-packing.
3. Binding
Once scheduled, the Controller binds the runner to a specific node:
- Reserves capacity on that node
- Updates the runner state to “Scheduled”
4. Provisioning
The Tarter daemon on the node receives the heartbeat response indicating a new runner assignment. It:
- Fetches the runner configuration from the Controller
- Clones a pre-built Tart VM image with Xcode and dependencies
- Starts the VM with the GitHub runner agent
- Reports status back: “Creating” -> “Running”
5. Execution
The runner registers with GitHub, picks up the workflow job, and executes it inside the Tart VM. Complete isolation means multiple runners can safely run on the same physical machine.
6. Cleanup
When the job completes, the runner VM stops automatically. The daemon detects this, reports “Finished” to the Controller, and releases the reserved capacity. The node is immediately available for new runners.
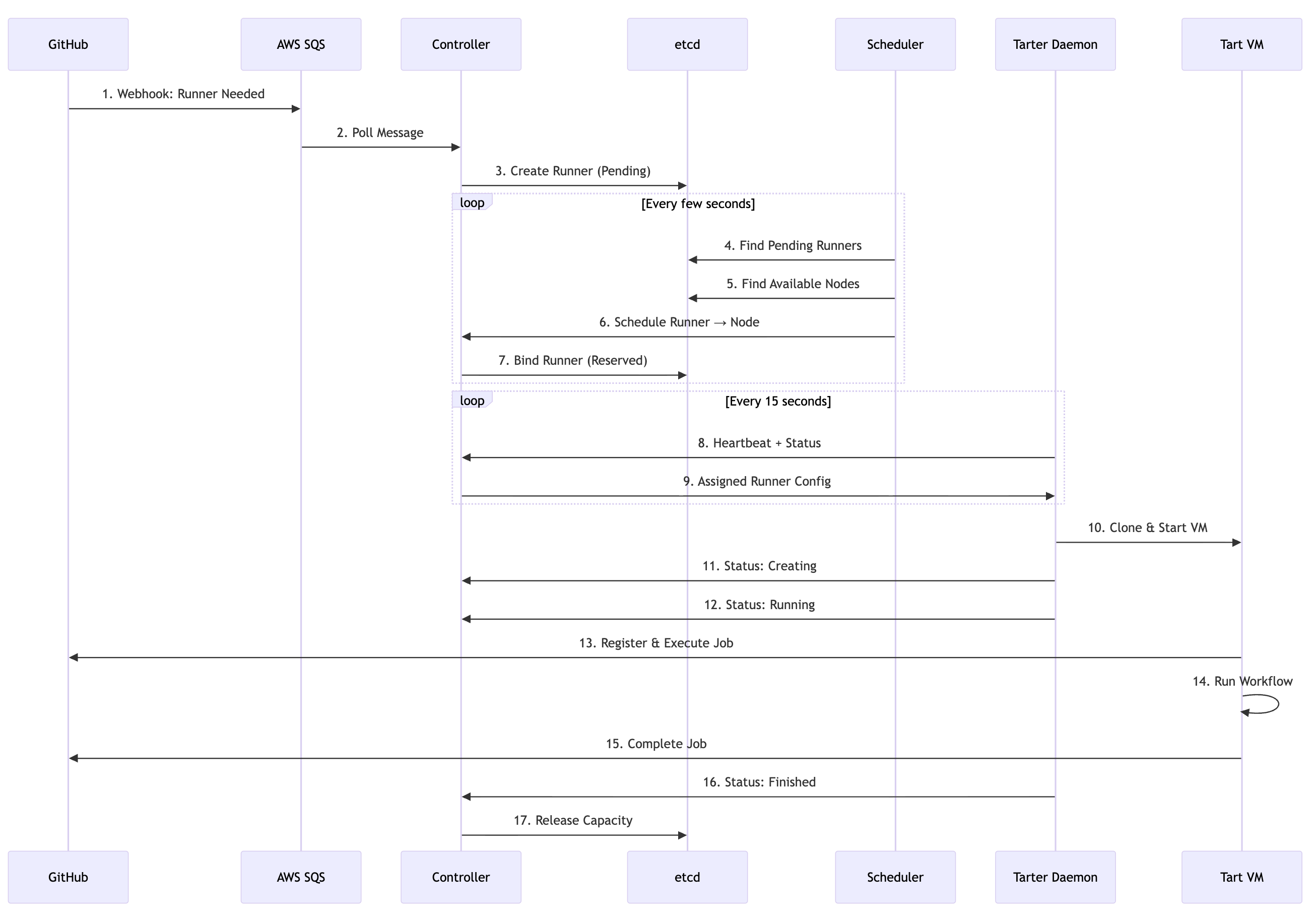 Figure 2: Complete runner lifecycle from GitHub webhook to job completion, showing interactions between all system components
Figure 2: Complete runner lifecycle from GitHub webhook to job completion, showing interactions between all system components
The Heartbeat Protocol
Every 15 seconds, each Tarter daemon sends a heartbeat to the Controller with:
- Current node status (CPU, memory, disk)
- List of running runners and their states
- Health check results
The Controller uses these heartbeats to:
- Detect failed nodes (no heartbeat = node is down)
- Track actual vs. desired state
- Make scheduling decisions based on real-time capacity
If a node misses multiple heartbeats, the Controller marks it unhealthy and stops scheduling new runners there.
Key Features That Made the Difference
Graceful Node Management
One of our biggest operational challenges was updating AMIs. Each EC2 Mac instance has pre-baked Tart VM images with specific Xcode versions and dependencies. Releasing a new Xcode version meant updating all nodes.
With our system, we can:
- Disable a node (mark it as unschedulable)
- Wait for existing runners to finish their jobs
- Terminate the instance once it’s drained
- Launch a new instance with the updated AMI
No interrupted workflows, no failed builds. The Controller’s node condition management makes rolling updates trivial.
Dynamic Scaling
The Scaler service adjusts capacity based on:
- Demand-Based Scaling: Monitors the pending runner queue. If runners are waiting too long, it triggers scale-up of the EC2 Auto Scaling Group.
- Schedule-Based Scaling: Reduces capacity during nights and weekends when usage is low. We don’t pay for 100 idle instances at 2 AM.
This alone cut our infrastructure costs significantly while ensuring capacity during business hours.
Observability
A metrics aggregator daemon runs on each node, exporting:
- Per-VM resource utilization
- Runner queue times
- Success/failure rates
- Node health metrics
This visibility lets us optimize capacity planning and catch issues before they impact developers.
The Technology Stack
To build this, we chose technologies that aligned with our operational needs:
- etcd: Distributed key-value store for state management. The Controller stores all node and runner state here, enabling high availability and strong consistency.
- AWS SQS: Decouples GitHub webhooks from the Controller. Runner requests queue up during traffic spikes without overwhelming the system.
- Tart: Apple’s native virtualization technology for macOS. Allows running multiple isolated macOS VMs on a single EC2 Mac instance, maximizing hardware utilization.
- Go: The entire platform is written in Go, leveraging its concurrency primitives and strong ecosystem for building cloud-native systems.
Results: The Numbers That Matter
After deploying to production with approximately 50 EC2 Mac nodes handling around 2,000 runners daily:
- Queue Time Reduction: Average queue times decreased from 90 minutes to under 15 minutes (p90), representing an 83% improvement in runner availability and a substantial enhancement to developer productivity.
- Cost Optimization: Infrastructure costs were significantly reduced through intelligent scaling. Off-hours capacity decreased by approximately 70% without affecting developer experience or service availability.
- Zero-Downtime Updates: Rolling AMI updates are now performed weekly without workflow interruptions. Graceful node draining ensures continuous service availability during maintenance operations.
- Improved Resource Efficiency: Bin-packing multiple runners per node increased effective capacity by approximately 40% compared to single-runner-per-instance allocation strategies.
This dramatic improvement in queue times has fundamentally transformed our development workflow. Developers now receive CI/CD feedback while context remains fresh, pull request iterations occur more rapidly, and the pipeline no longer represents a bottleneck in our software delivery process.
Key Learnings
Comprehensive Observability is Essential
From the initial deployment, we instrumented all system components with detailed metrics including heartbeat signals, queue times, scheduling latency, and VM provisioning duration. This comprehensive observability proved essential for both optimization and troubleshooting.
Design for Resilience
Infrastructure failures are inevitable—nodes fail, networks partition, and external APIs experience degradation. Implementing retry logic, circuit breakers, and graceful fallback mechanisms across all components ensured system stability even when dependencies experienced issues.
Distributed State Management Complexity
While etcd provided the strong consistency guarantees we required, we gained valuable experience managing watch connections, lease management, and partition tolerance. Distributed systems introduce inherent complexity that requires careful consideration and robust implementation.
Leverage Proven Patterns
Adopting Kubernetes concepts—including nodes, scheduling algorithms, desired state management, and reconciliation loops—provided a well-understood mental model that facilitated both implementation and team onboarding. These battle-tested patterns proved highly effective in our specific use case.
Future Enhancements
We continue to evolve the platform with several enhancements planned:
- Predictive Scaling: Leveraging historical usage patterns to anticipate demand and proactively scale infrastructure before queue buildup occurs
- Multi-Region Support: Distributing runner infrastructure across AWS regions to improve resilience and reduce latency
- Advanced Scheduling Logic: Incorporating additional factors such as job type, macOS version requirements, and team-specific constraints into scheduling decisions
Conclusion
Scaling macOS-based CI/CD infrastructure presents distinct challenges compared to Linux-based systems. Through this project, we successfully adapted proven orchestration patterns from Kubernetes to address the unique constraints of macOS virtualization, transforming a critical performance bottleneck into a robust, scalable platform.
The results speak to the effectiveness of this approach: an 83% reduction in queue times, significant cost optimization through intelligent scaling, and zero-downtime operational capabilities. More importantly, these improvements have enabled our development teams to maintain velocity and deliver value more effectively.
For organizations operating macOS CI/CD environments at scale, several key principles emerge from our experience:
- Platform-Specific Design: Generic solutions rarely address platform-specific constraints effectively. Purpose-built architecture yields superior results.
- Operational Excellence as a Priority: The ability to perform maintenance, updates, and scaling operations without disrupting running workflows is not optional at scale—it’s essential.
- Observability Drives Optimization: Comprehensive instrumentation and metrics collection enable data-driven decisions and continuous improvement.
- Proven Patterns Translate: While the implementation details differ, architectural patterns from Kubernetes—such as declarative state management, reconciliation loops, and heartbeat protocols—prove highly effective across different problem domains.
We believe this solution can benefit others facing similar challenges. The project is now open source and available on GitHub: tomtom-international/macos-actions-runner-controller
We welcome contributions, feedback, and discussions from the community. Whether you’re operating macOS runners at scale or just getting started, we hope this project provides a solid foundation for your CI/CD infrastructure.
This project was inspired by and builds upon concepts from actions-runner-controller, adapting them for the unique requirements of macOS environments.
Repository: https://github.com/tomtom-international/macos-actions-runner-controller
 TomTom and BentoML are advancing location-based AI together
TomTom and BentoML are advancing location-based AI together